MD5 加密原理&&实际应用
MD5 加密原理&&实际应用
原理
- MD5特点
- 唯一性,是有损加密,不可逆向,现有破解都是用撞库实现
- 不管多长的字符串,加密后长度都是一样长
- 唯一性:一个文件,不管多大,小到几k,大到几G,你只要改变里面某个字符,那么都会导致MD5值改变.
作用:很多软件和应用在网站提供下载资源,其中包含了对文件的MD5码,用户下载后只需要用工具测一下下载好的文件,通过对比就知道该文件是否有过更改变动. - 不可逆性
- MD5消息摘要算法,属Hash算法一类。MD5算法对输入任意长度的消息进行运行,产生一个128位的消息摘要。
- MD5的用处不是用来加密信息解密信息的,个人观点:用来做一个全局唯一标记,比如impdx或者图片文件产生的md5永远只会是一个值,我们不用去对比文件或者文本是否相同,只需要判断md5是否相同就可以判断了。
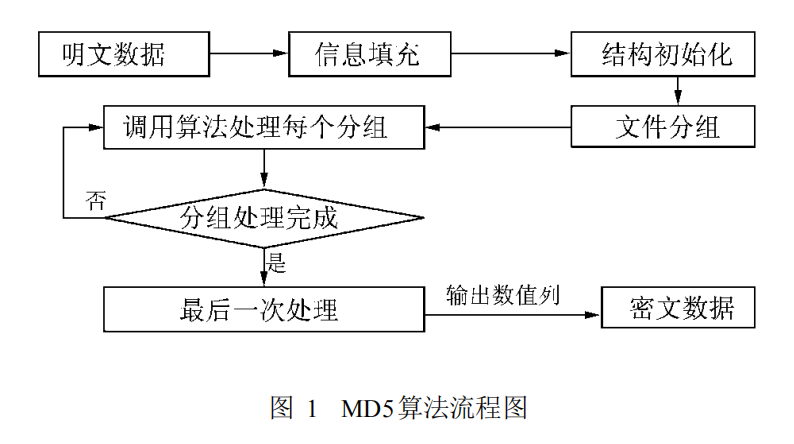
算法原理
1、数据填充
对消息进行数据填充,使消息的长度对512取模得448,设消息长度为X,即满足X mod 512=448。根据此公式得出需要填充的数据长度。
填充方法:在消息后面进行填充,填充第一位为1,其余为0。
2、添加消息长度
在第一步结果之后再填充上原消息的长度,可用来进行的存储长度为64位。如果消息长度大于264,则只使用其低64位的值,即(消息长度 对 264取模)。
在此步骤进行完毕后,最终消息长度就是512的整数倍。
3、数据处理
准备需要用到的数据:
- 4个常数: A = 0x67452301, B = 0x0EFCDAB89, C = 0x98BADCFE, D = 0x10325476;
- 4个函数:F(X,Y,Z)=(X & Y) | ((~X) & Z); G(X,Y,Z)=(X & Z) | (Y & (~Z)); H(X,Y,Z)=X ^ Y ^ Z; I(X,Y,Z)=Y ^ (X | (~Z));
把消息分以512位为一分组进行处理,每一个分组进行4轮变换,以上面所说4个常数为起始变量进行计算,
重新输出4个变量,以这4个变量再进行下一分组的运算,如果已经是最后一个分组,则这4个变量为最后的结果,即MD5值。
1 | 运算(6 & 2) |
具体计算的实现较为复杂,建议查阅相关书籍。

- 我们可以这么理解
X:字符串长度
要求
X mod 512=448
如果不行则加长度,进行填充,填充第一位为1,其余为0。
接着 长度如果超过2的64次方 位,只取低64位,即对 2的64取模
接着分组进行循环运算,最后换位就变成了加密MD5
MD5的用处
-
用来检验文件是否被修改,通常和sha1或者sha256配合检查,比如txt文件中修改了一个字母,那么他的md5会完全不相同。
-
对于某些明文密码传输,需要保护,普通加密方式具有可逆性,但是MD5不可逆。但常常不会单独使用MD5进行,因为通常的密码都可以通过撞库来获取(撞库:通过用空间换时间的方式,由于MD5的唯一性,我可以用计算机跑出任何字符串的MD5,比如12345的MD5,可以跑出来,也可以通过别人分享来获取)
实战利用PHP弱类型来比较MD5
-
例子只演示MD5在PHP中的漏洞
-
什么是弱类型,众所周知PHP是一门弱语言,不必向 PHP 声明该变量的数据类型,PHP 会根据变量的值,自动把变量的值转换为正确的数据类型,但在这个转换过程中就有可能引发一些安全问题。
-
当一个字符串被当作一个数值来取值,其结果和类型如下:如果该字符串没有包含’.',‘e’,'E’并且其数值值在整形的范围之内,该字符串被当作int来取值。其他所有情况下都被作为float来取值,该字符串的开始部分决定了它的值,如果该字符串以合法的数值开始,则使用该数值,否则其值为0。
题目来自于bugku
https://ctf.bugku.com/challenges/detail/id/94.html
一进去我们可以看到题目是用MD5,同时用?a=a显示false。
- 知识点
- PHP在处理哈希字符串时,会利用"!=“或”=="来对哈希值进行比较,它把每一个以"0E"开头的哈希值都解释为0,所以如果两个不同的密码经过哈希以后,其哈希值都是以"0E"开头的,那么PHP将会认为他们相同,都是0。
- 比如s1885207154a这串字符串通过MD5加密后为0e509367213418206700842008763514
攻击者可以利用这一漏洞,通过输入一个经过哈希后以"0E"开头的字符串,即会被PHP解释为0,如果数据库中存在这种哈希值以"0E"开头的密码的话,他就可以以这个用户的身份登录进去,尽管并没有真正的密码。
输入 a=s1885207154a
成功绕过
最后附上c++版本的MD5实现
1 |
|